
백엔드 엔지니어 이재혁
[Java] 멤버 변수를 굳이 지역 변수에 복사해서 쓰는 이유가 뭘까? 본문
`BlockingQueue`를 공부하며, `ArrayBlockingQueue`의 `put()` 메서드를 확인해보다가 의문점이 생겼다.
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// ...
/** Main lock guarding all access */
final ReentrantLock lock;
// ...
public ArrayBlockingQueue(int capacity, boolean fair) {
// ...
lock = new ReentrantLock(fair);
// ...
}
// ...
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
}
- `lock` 은 멤버 변수로 선언되었다.
- 생성자에서 `ReentrantLock`을 인스턴스화하고 `lock`이 참조하도록 했다.
- `put()` 메서드 내부에서, `final ReentrantLock lock = this.lock;` 멤버 변수를 지역 변수로 복사했다.
Q: 그냥 this.lock을 바로 사용해도 된다. 굳이 멤버 변수를 지역 변수 lock에 복사해서 사용하는 이유가 뭘까?
기본 패키지에 이렇게 작성되어 있으면 이유가 있겠지! 고민을 시작해봤다.
멤버 변수 참조 vs 지역 변수 참조
먼저, 공통적으로 `ArrayBlockingQueue`의 `put()` 메서드를 호출하는 상황을 가정하고 이야기하자.
이 상황에서는 호출한 스레드에 put 프레임이 올라가 있을 것이다.
그 다음, 멤버 변수를 참조하는 과정과 지역 변수를 참조하는 과정을 비교했다.
① 멤버 변수를 참조하는 경우

1. `this` 참조 + `lock` 참조. 두 번 거쳐 참조하는 상황. (2번 참조)
2. `put()` 메서드 기준으로 `lock` 객체는 두 번 사용되었다. (2번 사용)
단순화시키면 두 번 참조하는 메서드를 두 번 사용, 총 4번의 참조가 일어난다.
② 지역 변수를 참조하는 경우

1. `lock` 참조 (1번)
2. `put()` 메서드 기준으로 `lock` 객체는 두 번 사용되었다. (2번 사용)
단순화시키면 총 2번의 참조가 일어난다.
인스턴스 참조를 찾아가는 과정만 놓고보면 지역 변수에 복사해서 사용하는게 빨라 보인다. 하지만 지역 변수로 활용하려면 멤버 변수를 지역 변수로 복사하는 과정이 추가된다.
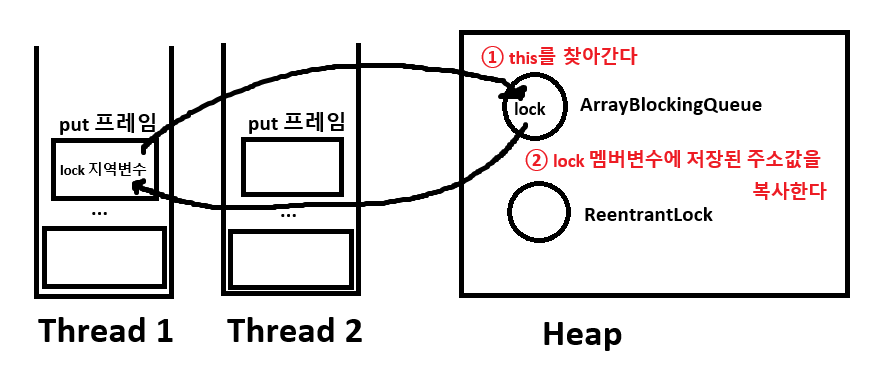
지역 변수로 저장하는 과정에서 1번의 참조가 일어나고, 1번의 값복사가 일어난다.
메서드 전체 과정을 다시 보면, 총 3번의 참조와 1번의 값복사가 일어나는 상황이다.
정리
멤버 변수를 사용하는 경우: 4번 참조
지역 변수를 사용하는 경우: 3번 참조 + 1번의 값복사
이렇게 보면 별 차이가 없어보인다.
멀티스레딩 관점에서 다시 생각해보자
`lock`을 지역 변수로 사용하는게 좋은 이유는 스레드가 락을 가지고 있는 시간을 최소화하기 위함이라고 생각된다.
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
멀티스레드 환경에서 위의 `put()` 메서드가 여러 스레드에서 동시에 실행된다고 가정해보자.
각 스레드는 `this.lock` 주소를 지역 변수에 복사하는 작업을 동시에 수행할 수 있다. 따라서, 스레드가 많아지더라도 지역 변수에 복사할 때 서로 다른 스레드의 실행 시간에 영향을 끼치지 않는다. 간단하게 주소값 복사에 멀티스레딩 비용이 들지 않는다고 표현해보겠다.
중요한 부분은 `lock.unlock();`이다. 멀티스레드 환경에서 한 스레드가 `lock.unlock();`을 완료해야 또 다른 스레드가 임계구역의 작업을 실행할 수 있다. `this.lock.unlock();` 같이 실행한다고 하면, 임계구역을 벗어나 다른 스레드에게 락을 넘겨주기까지 소요되는 시간에 "멤버 변수 참조 시간"이 추가로 들어가게 된다.
결론
멤버 변수 주소값 읽기 자체는 thread-safe한 작업이다. 이런 관점에서 멤버 변수를 참조하는 단계는 임계 구역 밖에서 처리해주는 것이 락 해제를 더 빠르게 하고, 멀티 스레딩 환경에서 더 나은 성능을 보여줄 수 있다고 생각된다.
추가 정보
참조에 드는 비용보다는 락 해제 과정 자체가 훨씬 큰 비용이 들기 때문에 성능 향상이 미미하다고는 한다.
`ArrayBlockingQueue`는 많이 사용되는 동시성 패키지다보니 미세한 최적화라도 최대한 해놓은 것 같다.
하지만 가독성 및 유지보수성 측면에서도 도움이 되기 때문에 직접 짤 때도 지역 변수로 많이 작성한다고 한다.
Java JIT 컴파일러가 이런 과정을 코드에 작성하지 않아도 알아서 최적화해주기도 한다고 한다.
* JIT 컴파일러: 자바 프로그램이 실행되는 도중에, 자주 사용되는 코드를 기계어로 변환(컴파일)해서 실행 속도를 높여주는 컴포넌트
'흥미로운 것들' 카테고리의 다른 글
| 진짜 REST API와 HATEOAS (0) | 2025.07.13 |
|---|---|
| [Java] MapN의 비트 연산 사용 (0) | 2025.06.18 |
| [Java] List.of() 메서드 (0) | 2025.06.18 |
| [Java] Java 언어와 JVM (1) | 2025.06.05 |
| [CS] CPU 캐시 메모리의 흥미로운 점들 (0) | 2025.05.22 |
